
GPU-accelerated HMM
Date:
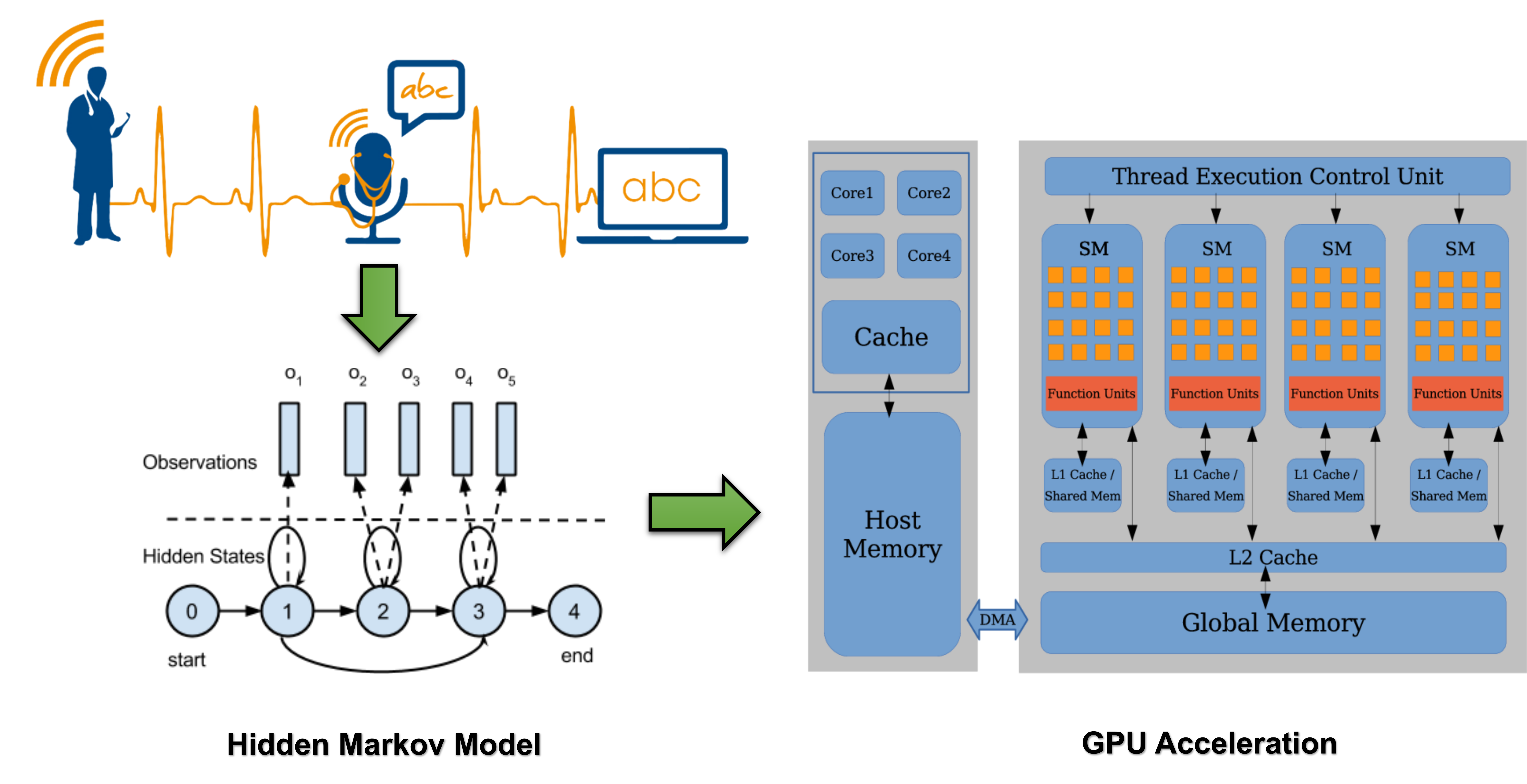
Hidden Markov Models (HMMs) is one of the most popular algorithms used in speech recognition. Training and testing an HMM is computationally intensive and time-consuming. We developed a GPU-accelerated HMM to improve execution efficiency.
An HMM requires 3 parameters:
- the prior probability
- a state transition probability matrix
- an emission probability matrix
To train an HMM, 3 stages are implemented
- Forward stage, where we compute the likelihood of being in the state(i) at time t after having observed the sequence from the start until t
- Backward stage, where we compute the likelihood of being in the state(i) at time t, given observing the rest of the sequence
- Expectation-Maximization (EM) stage, where we estimate the distribution over the states when the system is at time t, and maximize the probability of the observation sequence by updating the HMM parameters.
In this project, we provide a parallelized Hidden Markov Model to accelerate isolated words speech recognition. We experiment with different optimization schemes and make use of optimized GPU computing libraries to speed up the computation on GPUs. We also explore the performance benefits of using advanced GPU features for concurrent execution of multiple compute kernels. The algorithms are evaluated on multiple Nvidia GPUs using CUDA as a programming framework. Our GPU implementation achieves better performance than traditional serial and multi-threaded implementations. When considering the end-to-end performance of the application, which includes both data transfer and computation, we achieve a 9x speedup for training with the use of a GPU over a multi-threaded version optimized for a multi-core CPU.
One of the image is from here.