
Monte Carlo eXtreme
Date:
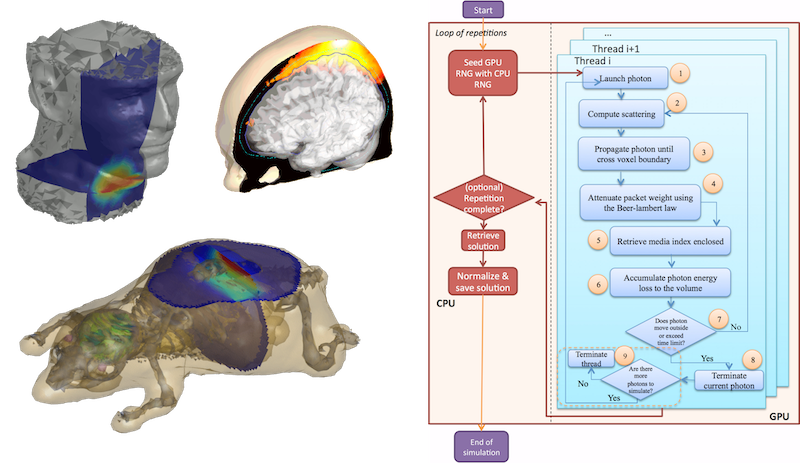
The Monte Carlo (MC) method has been widely regarded as the gold-standard for modeling light propagation inside complex random media, such as human tissues. It, however, suffers from low computational efficiency because a large number of photons have to be simulated to achieve desired solution quality with low stochastic noise. Sequential MC simulation implementations require extensive computation and long run-time, typically ranging from several hours to several days. In this project named Monte Carlo eXtreme (MCX), we developed CUDA and OpenCL implementations to leverage the computing power of GPUs.
For CUDA-based MCX, we developed several optimization schemes to improve the simulation speed.
- We wrote a customized nextafter function used in hitgrid function, where a hitgrid function compute the intersection of the ray when a photon reaches a voxel boundary.
- We optimized the random number generator (RNG) based on the xorshift128+ algorithm, which uses integer operations instread of single precision operations. RNG is used to compute the scattering event, including the angle and length.
- We adopted c++ templates to generate specialized photon injection kernels to simplify the kernel computation and control flow.
- We developed an kernel configuation scheme to dyanmically determine a balanced solution for different NVIDIA GPU architectures, rather than using a fixed number of threads for the MCX kernel.
- We optmized the utilization of shared memory and registers to achieve a higher occupany level for the GPU kernel.
For OpenCL-based MCX (MCXCL), we also developed similar features like MCX. In addition, we have investigated other techniques to explore the portability and scalability.
First, we noticed the workload balancing issue due to the random nature of the simulation, where some threads are idle while others are still migrating the photons. We developed a dynamic load balancing strategy at the workgroup-level , instead of the thread-level. In this scheme, we divide the total number of the photon by the number of workgroups of the kernel. Within each workgroup, each thread will check whether there are any remaining photons (stored in the local memory). If so, the thread will simulate a photon migration and atomically deduct the workgroup workload by 1. Overall, workgroup-level balancing can outperform the default setup.
Second, we achieved a linear performance scaling when the GPUs are identical on a multi-group system, where we evenly divided the total number of photons across all the accelerators. For a heterogenous GPU system, however, dipatching the workload without considering the compute capability of the available devices will lead to poor resource utilization. To solve this issue, we compare three different schemes by distributing the photon simulation according to 1) the (GPU) compute units or (CPU) cores, 2) throughput of the device estimated via a linear performance model, and 3) the solution to a linear programming problem (using fminimax in MATLAB). Based on our results, the proposed throughput model produces a close-to-ideal balancing performance.
To sum up, we analyzed the characteristics of the MCX kernel and developed several optimization schemes to improve the execution efficiency for both single-GPU and multi-GPU systems.